陈宁,男,1995年生,博士,讲师,硕士生导师。2024年6月博士毕业于南京大学计算机科学与技术学院,师从陆桑璐教授和张胜副教授;同年7月进入苏州大学计算机科学与技术学院工作。研究方向为边缘智能,即人工智能应用(如视频分析、视频增强)在网络边缘端的高效部署,具体涉及计算卸载、资源调度、分布式模型训练和推理、云边端协同机制。目前,在权威会议IEEE INFOCOM, ICDE, SECON, ICPP和期刊IEEE/ACM TON, IEEE TPDS, IEEE TMC,Computer Networks上累计发表论文18篇。担任多个期刊和会议审稿人,包括IEEE INFOCOM、IEEE TMC、IEEE MASS等。
更多信息欢迎访问我的英文主页:https://nju-cn.github.io/
聚焦于边缘视频推理系统优化,旨在资源受限的边缘环境中实现低延迟、低能耗和高性能的视频推理效果。具体而言,我的研究涵盖以下三个核心子方向:
视频配置自适应。在边缘计算环境中,由于硬件资源(如计算能力、内存和电池续航)的限制,网络带宽的不确定性,以及视频内容的多样性,传统固定配置的方法使得视频推理的实时性和精度都面临巨大挑战。因而,考虑通过动态调整视频配置(如分辨率、帧率、压缩率、码率等),使其在不同资源供给条件下依然能最优化系统性能,满足时延和精度需求。
云边端协作机制。边缘设备资源有限,而视频推理任务(如视频分析、增强)通常是计算和存储密集型的,因而考虑根据视频任务的复杂性和时效性,设计任务的分层架构,将不同的任务合理分配到云、边缘、终端。例如,边缘设备利用其CPU进行视频预处理(如帧过滤、ROI提取、结果缓存等),边缘服务器执行具体的视频推理,云端则根据视频内容的动态性进行模型训练和微调,并通过剪枝、压缩等手段轻量化推理模型。
异构设备协同推理。单设备推理无法保障实时性,而随着智能摄像头等设备的广泛部署,我们考虑多异构设备协同来加速推理。协同方式分为以下两种:(1)模型切割并分布式部署:基于异构设备运行时状态和模型中间数据大小,将模型分成多块并部署在多个异构设备,通过流水线串行方式增加吞吐量并降低平均处理时延;(2)数据切分并行卸载:基于视频特征将数据切分,并卸载至异构设备实现并行推理,从而加快推理速度。
更多信息欢迎访问我的英文主页:https://nju-cn.github.io/
系统简介
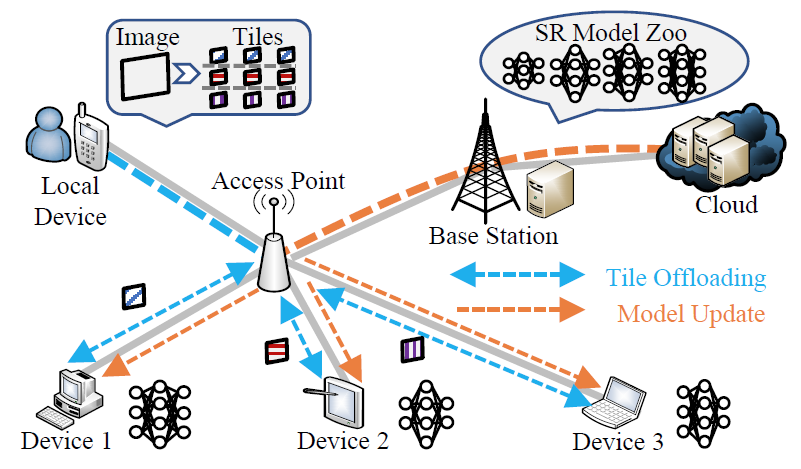
TileSR: 基于并行卸载的边缘视频增强加速(一作)
1.问题描述与目标:考虑到单移动设备端无法推理较高分辨率图片,同时视频增强模型通常是DAG型,因而采用视频块多设备并行推理架构,然而切块粒度及设备运行时状态都显著影响系统性能;目标是最大化推理性能,同时保持实时性;
2.系统设计:1)基于推理难度的块选择:预实验发现视频块推理难度分布不均,而难度小的块在在本地使用数学插值亦取得高PSNR,因而选取top-k难度最大块作为卸载对象;2)块并行卸载:使用多臂赌博机算法,实现块与设备之间的卸载映射。
3.工作成果:基于多个边缘设备的真实实验表明TileSR显著降低17.77%-82.2% 的响应时延,同时在视频SR 质量上实现了2.38% 至10.57% 的提升。本工作已发表于CCF-A 会议 IEEE INFOCOM 2024。
----------------------------------------------------------------------------------------------------------
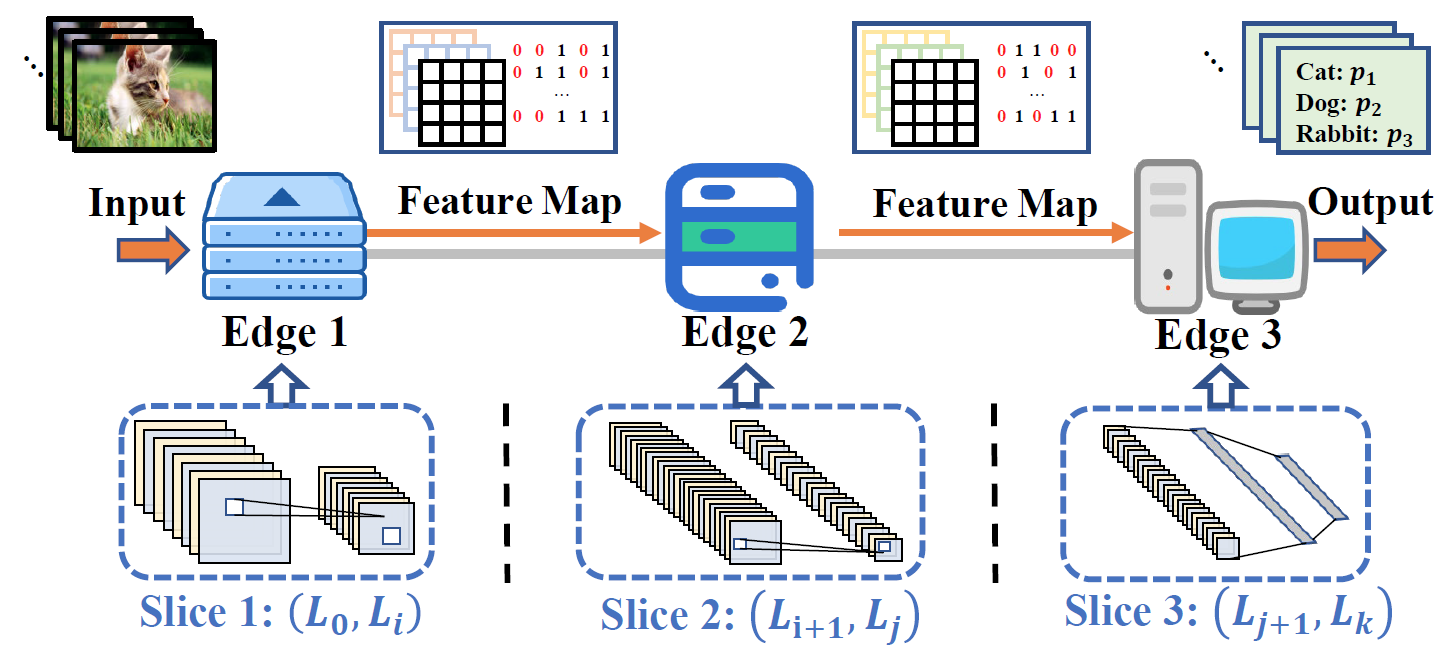
ResMap: 多边缘设备协同视频分析系统的传输优化(一作)
1.问题描述与目标:考虑到单个设备推理的资源瓶颈,当前不少工作采用多设备协同处理的思想,即通过序列化执行模型的各个部分,并经过多次中间数据传递,输出最终结果。然而中间数据量规模庞大,严重降低视频帧流水线执行的性能。本工作旨在最大力度压缩中间数据,最小化平均处理时延;
2.系统设计:1)特征图稀疏编码:类似于视频帧间编码,相邻帧经同一层神经网络传播输出相似特征图,其剩余图呈现稀疏性,可使用矩阵编码高度压缩;2)稀疏度预测机制:基于第一层稀疏度,按照层类别如卷积和池化,直接预测后续所有层的稀疏度;3)模型切割:基于各层预测数据量,采用动态规划得到当前最优模型切割方案;
3.工作成果:相较于经典负载均衡策略,ResMap在模型AlexNet, ResNet, VGG, GoogLeNet上能实现14.93%-46.12%的数据量减少,以及17.43%-46.12%的平均处理时间缩减。本工作已发表于CCF-A 会议 IEEE INFOCOM 2023。
----------------------------------------------------------------------------------------------------------
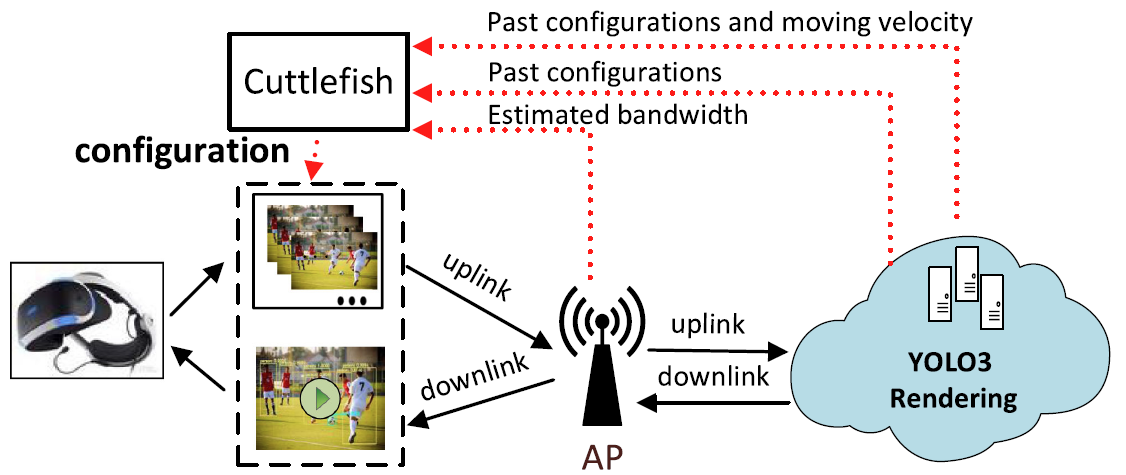
Cuttlefish: 面向边缘端视频分析应用的配置决策(一作)
1.问题描述与目标:边缘网络带宽抖动剧烈,视频内容时变多样,使用固定配置编码、传输以及推理视频可能会导致端到端时延增加、分析准确度下降等问题。本工作旨在设计一种自适应视频配置决策系统,以匹配网络和视频内容的波动;
2.系统设计:1)配置细粒度化:引入RoI思想,分别为块内和块外配置;2)多维影响因子:网络带宽和视频内容如物体速度都会影响视频分析性能,基于LSTM预测带宽,将物体在帧间移动的曼哈顿距离作为速度;3)配置决策方案:将带宽、速度、历史配置等信息耦合成状态向量,采用基于A3C的强化学习算法学习最优配置;
3.工作成果:采用FCC traces和YouTube上的行人和车辆视频,并以NVIDIA Jetson TX2作为边缘设备来验证Cuttlefish性能。对比已有策略,Cuttlefish能实现18.4%-25.8%的累积reward提升。本项目发表于CCF-A 期刊IEEE TPDS。
----------------------------------------------------------------------------------------------------------
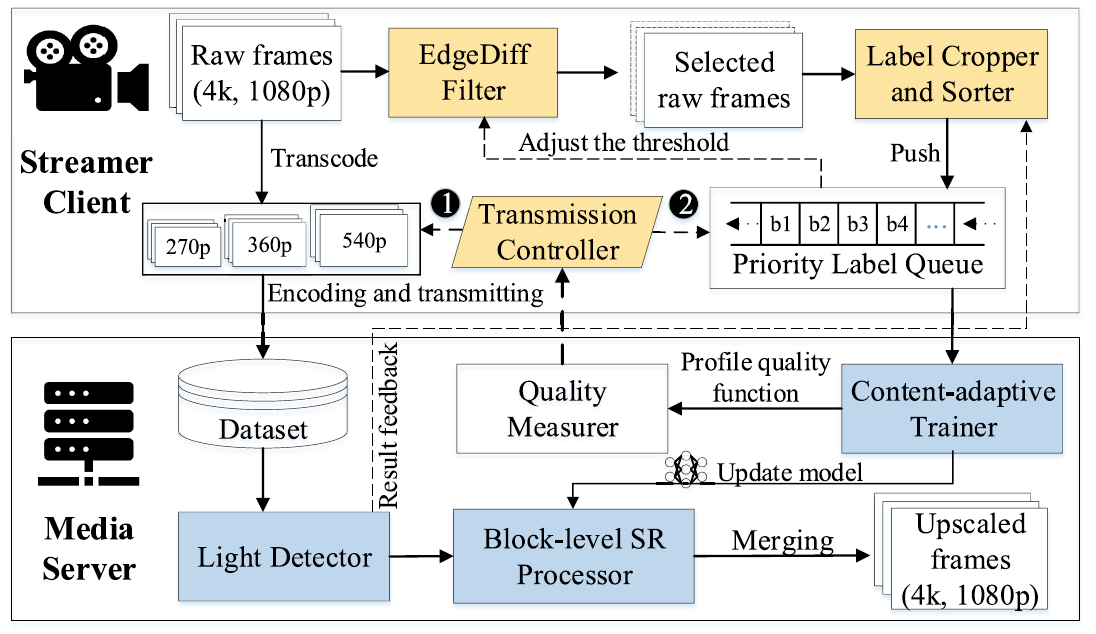
ViChaser:基于观众驻点的自适应视频超分辨率系统(一作)
1.问题描述与目标:直播端到媒体服务间的网络带宽抖动剧烈,媒体服务器资源受限等问题,极大的影响了下行用户持续观看高质量视频的需求。本工作旨在最大化利用上行带宽,实时重构高质量直播视频,满足下行用户多样化需求;
2.系统设计:1)块级SR:缩小输入尺寸能大幅度降低超分辨率的重构时延,同时观众驻点区域时变;2)模型在线训练:在线训练SR模型以适应内容变化,其中训练样本为高质量驻点区域;3)决策优化:采用Lyapunov优化算法为低质量版本视频和训练样本分配传输带宽;4)块优先级排序:设计EdgeDiff过滤器进行帧级筛选,并采用yolov5捕获用户驻点区域,并提出标签优先级队列来存储标签以最大化重构质量;
3.工作成果:采用YouTube上的四类直播视频,并以NVIDIA Jetson TX2作为媒体服务器来验证ViChaser性能。对比已有策略如WebRTC和LiveNAS,ViChaser能提高11-16的帧处理速率。本项目已发表于CCF-A 期刊 IEEE TON。
----------------------------------------------------------------------------------------------------------
与顶尖学者同行,探索学术与创新的无限可能!
你所担心的 VS. 我们能给你的
✔️是否能够按时毕业?VS.提供前沿idea + 定期组会指导 + 权威论文写作指导 + 绝不抢一作
✔️团队氛围如何? VS. 定期组织团建和聚餐,诗意苏州我们带你走遍
✔️是否具有出国开会或交换的机会? VS. 组里经费充足,至少支持每个学生出国开会一次;至于交换,可提供补贴
✔️是否允许实习? VS. 当然允许实习 + 我们亦可联系大厂提供实习机会
招生方向 (不需要擅长,我们更希望你对其有好奇心和热爱)
✔️计算机网络(网络流量测量)
✔️人工智能(计算机视觉)
✔️边缘计算(端侧模型推理与训练)
✔️当然,若你所感兴趣或擅长的方向不在上述,也欢迎你带我学习与成长,为我组开门立户,发扬光大!
此刻,你离突破性发现只差一次勇敢的选择!
联系方式
邮箱:ningc@suda.edu.cn 手机号:18983676944
陈宁,男,1995年生,博士,讲师,硕士生导师。2024年6月博士毕业于南京大学计算机科学与技术学院,师从陆桑璐教授和张胜副教授;同年7月进入苏州大学计算机科学与技术学院工作。研究方向为边缘智能,即人工智能应用(如视频分析、视频增强)在网络边缘端的高效部署,具体涉及计算卸载、资源调度、分布式模型训练和推理、云边端协同机制。目前,在权威会议IEEE INFOCOM, ICDE, SECON, ICPP和期刊IEEE/ACM TON, IEEE TPDS, IEEE TMC,Computer Networks上累计发表论文18篇。担任多个期刊和会议审稿人,包括IEEE INFOCOM、IEEE TMC、IEEE MASS等。
更多信息欢迎访问我的英文主页:https://nju-cn.github.io/
聚焦于边缘视频推理系统优化,旨在资源受限的边缘环境中实现低延迟、低能耗和高性能的视频推理效果。具体而言,我的研究涵盖以下三个核心子方向:
视频配置自适应。在边缘计算环境中,由于硬件资源(如计算能力、内存和电池续航)的限制,网络带宽的不确定性,以及视频内容的多样性,传统固定配置的方法使得视频推理的实时性和精度都面临巨大挑战。因而,考虑通过动态调整视频配置(如分辨率、帧率、压缩率、码率等),使其在不同资源供给条件下依然能最优化系统性能,满足时延和精度需求。
云边端协作机制。边缘设备资源有限,而视频推理任务(如视频分析、增强)通常是计算和存储密集型的,因而考虑根据视频任务的复杂性和时效性,设计任务的分层架构,将不同的任务合理分配到云、边缘、终端。例如,边缘设备利用其CPU进行视频预处理(如帧过滤、ROI提取、结果缓存等),边缘服务器执行具体的视频推理,云端则根据视频内容的动态性进行模型训练和微调,并通过剪枝、压缩等手段轻量化推理模型。
异构设备协同推理。单设备推理无法保障实时性,而随着智能摄像头等设备的广泛部署,我们考虑多异构设备协同来加速推理。协同方式分为以下两种:(1)模型切割并分布式部署:基于异构设备运行时状态和模型中间数据大小,将模型分成多块并部署在多个异构设备,通过流水线串行方式增加吞吐量并降低平均处理时延;(2)数据切分并行卸载:基于视频特征将数据切分,并卸载至异构设备实现并行推理,从而加快推理速度。
更多信息欢迎访问我的英文主页:https://nju-cn.github.io/
系统简介
TileSR: 基于并行卸载的边缘视频增强加速(一作)
1.问题描述与目标:考虑到单移动设备端无法推理较高分辨率图片,同时视频增强模型通常是DAG型,因而采用视频块多设备并行推理架构,然而切块粒度及设备运行时状态都显著影响系统性能;目标是最大化推理性能,同时保持实时性;
2.系统设计:1)基于推理难度的块选择:预实验发现视频块推理难度分布不均,而难度小的块在在本地使用数学插值亦取得高PSNR,因而选取top-k难度最大块作为卸载对象;2)块并行卸载:使用多臂赌博机算法,实现块与设备之间的卸载映射。
3.工作成果:基于多个边缘设备的真实实验表明TileSR显著降低17.77%-82.2% 的响应时延,同时在视频SR 质量上实现了2.38% 至10.57% 的提升。本工作已发表于CCF-A 会议 IEEE INFOCOM 2024。
----------------------------------------------------------------------------------------------------------
ResMap: 多边缘设备协同视频分析系统的传输优化(一作)
1.问题描述与目标:考虑到单个设备推理的资源瓶颈,当前不少工作采用多设备协同处理的思想,即通过序列化执行模型的各个部分,并经过多次中间数据传递,输出最终结果。然而中间数据量规模庞大,严重降低视频帧流水线执行的性能。本工作旨在最大力度压缩中间数据,最小化平均处理时延;
2.系统设计:1)特征图稀疏编码:类似于视频帧间编码,相邻帧经同一层神经网络传播输出相似特征图,其剩余图呈现稀疏性,可使用矩阵编码高度压缩;2)稀疏度预测机制:基于第一层稀疏度,按照层类别如卷积和池化,直接预测后续所有层的稀疏度;3)模型切割:基于各层预测数据量,采用动态规划得到当前最优模型切割方案;
3.工作成果:相较于经典负载均衡策略,ResMap在模型AlexNet, ResNet, VGG, GoogLeNet上能实现14.93%-46.12%的数据量减少,以及17.43%-46.12%的平均处理时间缩减。本工作已发表于CCF-A 会议 IEEE INFOCOM 2023。
----------------------------------------------------------------------------------------------------------
Cuttlefish: 面向边缘端视频分析应用的配置决策(一作)
1.问题描述与目标:边缘网络带宽抖动剧烈,视频内容时变多样,使用固定配置编码、传输以及推理视频可能会导致端到端时延增加、分析准确度下降等问题。本工作旨在设计一种自适应视频配置决策系统,以匹配网络和视频内容的波动;
2.系统设计:1)配置细粒度化:引入RoI思想,分别为块内和块外配置;2)多维影响因子:网络带宽和视频内容如物体速度都会影响视频分析性能,基于LSTM预测带宽,将物体在帧间移动的曼哈顿距离作为速度;3)配置决策方案:将带宽、速度、历史配置等信息耦合成状态向量,采用基于A3C的强化学习算法学习最优配置;
3.工作成果:采用FCC traces和YouTube上的行人和车辆视频,并以NVIDIA Jetson TX2作为边缘设备来验证Cuttlefish性能。对比已有策略,Cuttlefish能实现18.4%-25.8%的累积reward提升。本项目发表于CCF-A 期刊IEEE TPDS。
----------------------------------------------------------------------------------------------------------
ViChaser:基于观众驻点的自适应视频超分辨率系统(一作)
1.问题描述与目标:直播端到媒体服务间的网络带宽抖动剧烈,媒体服务器资源受限等问题,极大的影响了下行用户持续观看高质量视频的需求。本工作旨在最大化利用上行带宽,实时重构高质量直播视频,满足下行用户多样化需求;
2.系统设计:1)块级SR:缩小输入尺寸能大幅度降低超分辨率的重构时延,同时观众驻点区域时变;2)模型在线训练:在线训练SR模型以适应内容变化,其中训练样本为高质量驻点区域;3)决策优化:采用Lyapunov优化算法为低质量版本视频和训练样本分配传输带宽;4)块优先级排序:设计EdgeDiff过滤器进行帧级筛选,并采用yolov5捕获用户驻点区域,并提出标签优先级队列来存储标签以最大化重构质量;
3.工作成果:采用YouTube上的四类直播视频,并以NVIDIA Jetson TX2作为媒体服务器来验证ViChaser性能。对比已有策略如WebRTC和LiveNAS,ViChaser能提高11-16的帧处理速率。本项目已发表于CCF-A 期刊 IEEE TON。
----------------------------------------------------------------------------------------------------------
与顶尖学者同行,探索学术与创新的无限可能!
你所担心的 VS. 我们能给你的
✔️是否能够按时毕业?VS.提供前沿idea + 定期组会指导 + 权威论文写作指导 + 绝不抢一作
✔️团队氛围如何? VS. 定期组织团建和聚餐,诗意苏州我们带你走遍
✔️是否具有出国开会或交换的机会? VS. 组里经费充足,至少支持每个学生出国开会一次;至于交换,可提供补贴
✔️是否允许实习? VS. 当然允许实习 + 我们亦可联系大厂提供实习机会
招生方向 (不需要擅长,我们更希望你对其有好奇心和热爱)
✔️计算机网络(网络流量测量)
✔️人工智能(计算机视觉)
✔️边缘计算(端侧模型推理与训练)
✔️当然,若你所感兴趣或擅长的方向不在上述,也欢迎你带我学习与成长,为我组开门立户,发扬光大!
此刻,你离突破性发现只差一次勇敢的选择!
联系方式
邮箱:ningc@suda.edu.cn 手机号:18983676944